¶ 10 Julkaisualustan kehittäminen osa A
2025-05-23
bSF Julkaisualusta - Uusi tapa suunnitella, tuottaa ja julkaista teknisiä määrittelyjä!
Oletko koskaan miettinyt, miten monimutkaiset tekniset ohjeet ja standardit saadaan helposti ymmärrettäviksi ja käytännöllisiksi? bSF (buildingSMART Finland) on kehittämässä ratkaisua, joka mullistaa tavan, jolla tekniset määrittelyt laaditaan ja julkaistaan – niin, että tietokoneet "ymmärtävät" ne samoin kuin ihmiset.
¶ Johdanto
Rakennettuun ympäristöön liittyvät ohjeistukset ja vaatimukset ovat täällä hetkellä monimutkainen ja osin ristiriitainen kokonaisuus, joka pohjautuu moniin erilaisiin standardeihin, säädöksiin, ohjeisiin ja sanastoihin. Vaikka osa näistä on saatu harmonisoitua ja teknisesti yhteentoimivaksi, ihmispohjainen tulkinta on edelleen merkittävässä roolissa. Tämä tilanne aiheuttaa monia haasteita, kuten tiedon validoinnin ja verifioinnin vaikeuksia, tiedon hallinnan automaation estämistä sekä kohonneita riskejä virheelliselle resurssien käytölle. Keskeisenä syynä pulmiin on se, että tieto ei ole koneluettavasti semanttisesti yhteentoimivaa, eli koneymmärrettävää.
Nykytilanteessa eri järjestelmien ja KiRa-alan toimijoiden välillä tiedon merkitys vaatii manuaalista työtä, mikä tekee tiedon muunnosten rakentamisesta ja ylläpidosta vaativaa. Tämä kuluttaa resursseja ja altistaa virheille. Lisäksi PDF-asiakirjoihin perustuvat määritykset sisältävät riskejä, kuten ajantasaisuuden ja viittauksien vanhentumisen. Rakennettuun ympäristöön liittyvät käsitteet ovat usein epämääräisesti määriteltyjä, mikä hankaloittaa tiedon automaattista varmentamista, analysointia ja hyödyntämistä.
Projektin keskeinen tavoite oli kehittää ratkaisu, joka tukee rakennetun ympäristön tietojen semanttista yhteentoimivuutta. Tämä saavutetaan luomalla julkaisualusta, jossa rakennetun ympäristön tiedot ja määrittelyt kyetään tuottamaan ja julkaisemaan ihmis- ja koneluettavassa sekä koneymmärrettävässä muodossa.
Projektissa kehitettiin julkaisumalli sekä teknologiset määrittelyt, jotka sisältävät teknisen dokumentaation sekä arkkitehtuurin kuvauksen, toimintatapaa demonstroivan PoCin sekä suunnitelman julkaisualustan toteuttamiseksi, sisältäen arvion kustannuksista ja aikataulusta. Tavoitteena on kehittää projektin seuraavassa osassa (Julkaisualustan kehittäminen osa B) kiinteistö- ja rakentamisalan toimijoille suunnattu julkaisualusta, joka tukee näiden tavoitteiden toteutumista.
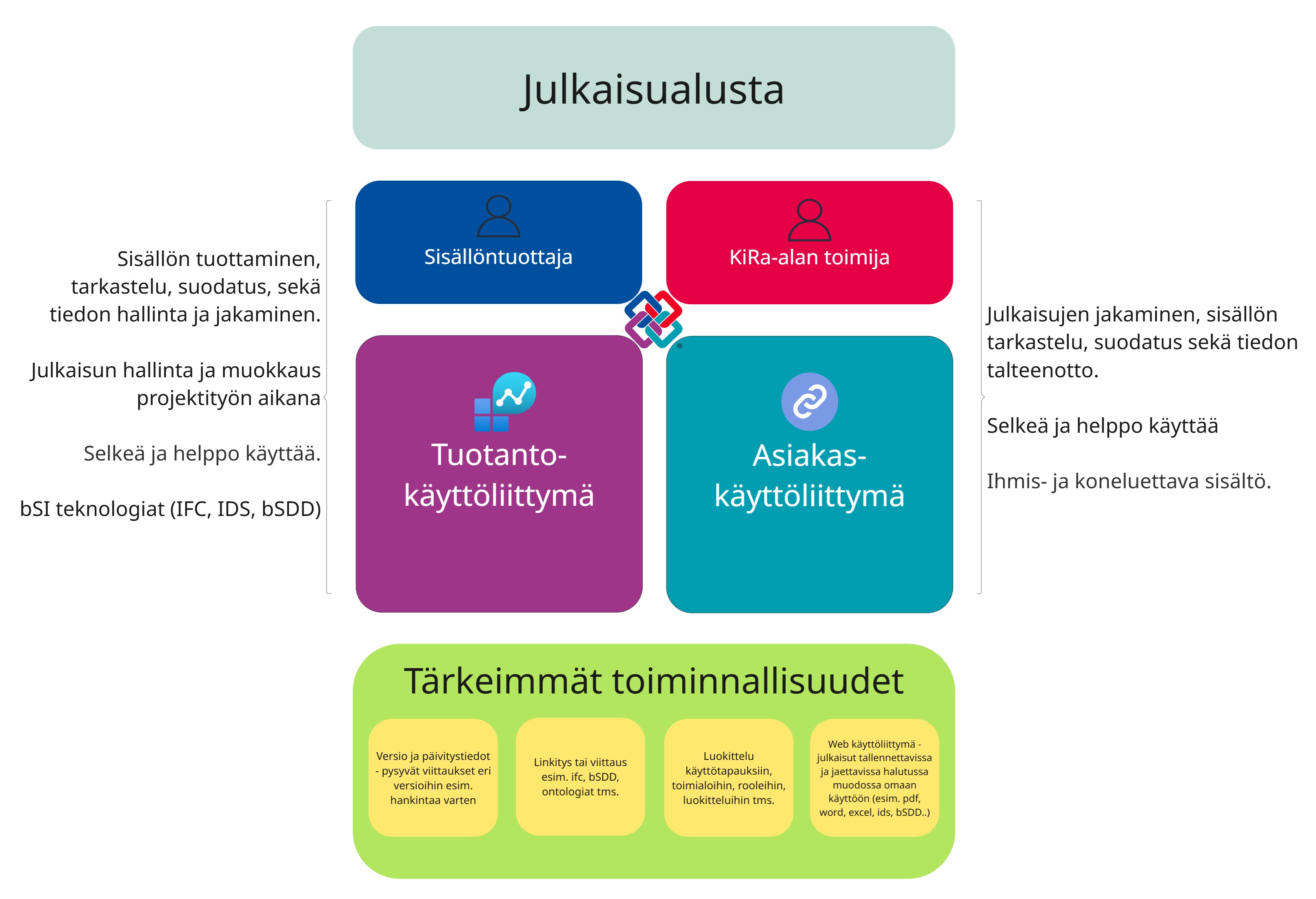
Julkaisualusta tulee koostumaan kahdesta käyttäjälle näkyvästä käyttöliittymästä.
- Tuotantokäyttöliittymässä tuotetaan ja hallinnoidaan julkaisuja, kuten ohjeita, vaatimuksia, nimikkeistöjä tai tiedonsiirtomäärityksiä.
- Asiakaskäyttöliittymässä jaetaan ja käytetään tuotettuja julkaisuja ihmis- ja koneymmärrettävässä muodossa.
Julkaisumallin ja julkaisuympäristön kuvaukset on kuvattu tarkemmin kappaleissa Julkaisumalli ja Julkaisualusta sekä Jatkotoimenpiteet.
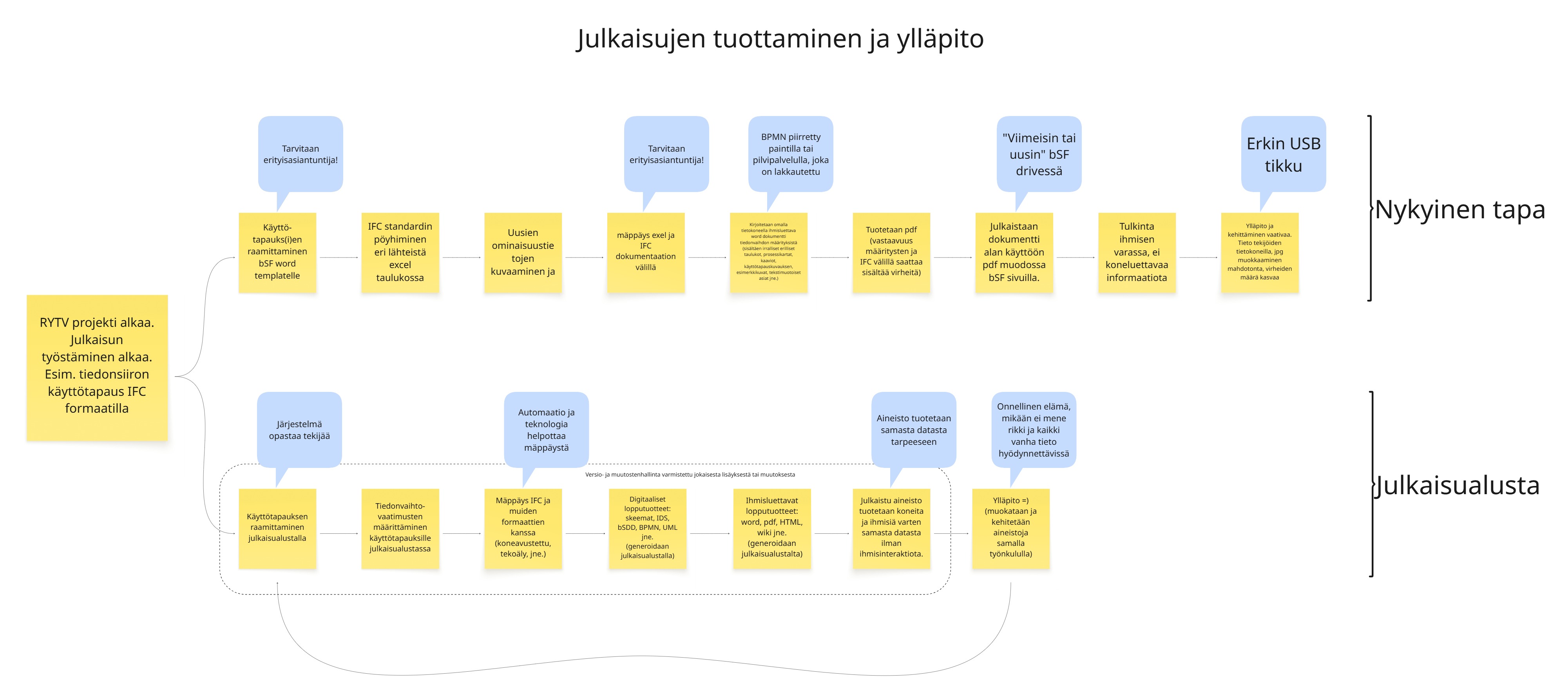
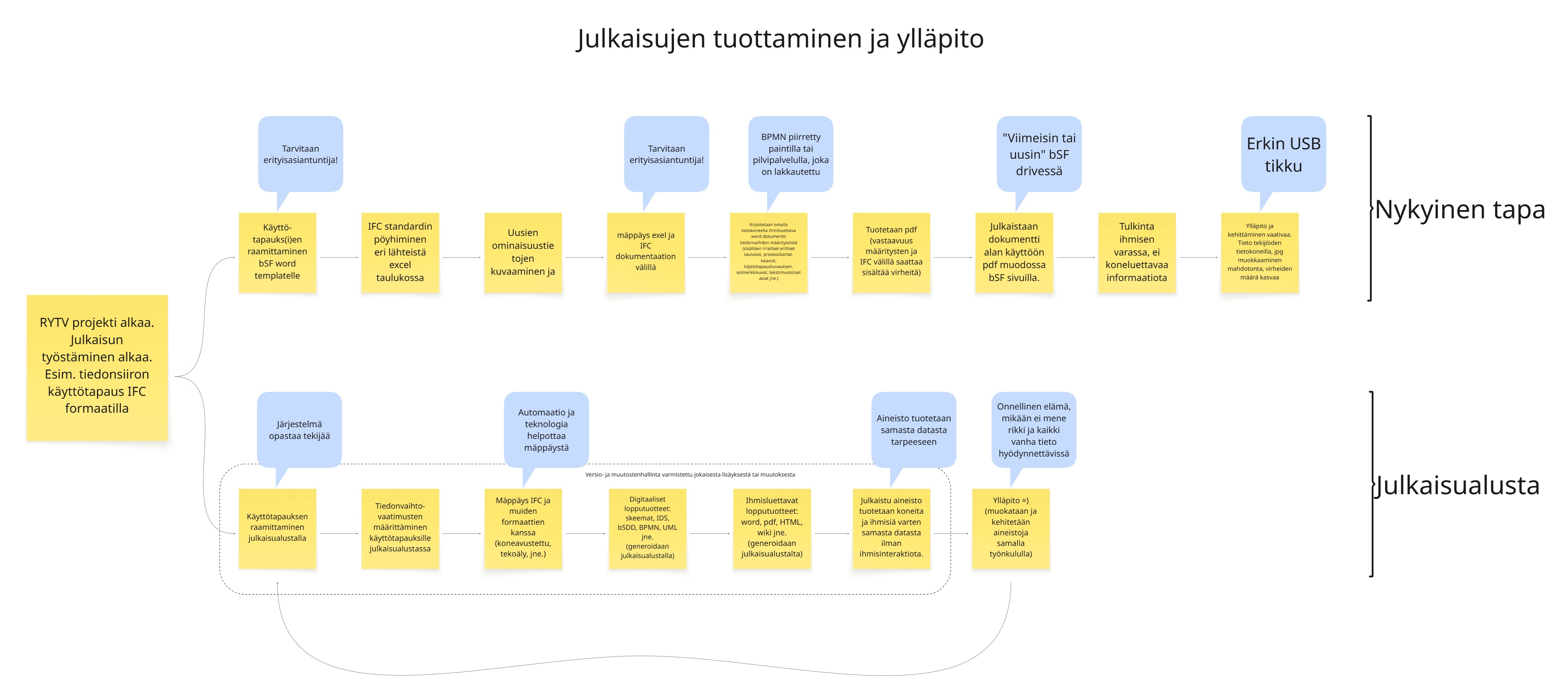
Julkaisujen tuottamista julkaisumallin mukaisesti on kuvattu seuraavassa kuvassa. Kuvassa verrokkina myös nykyinen tapa.
{kind=link}
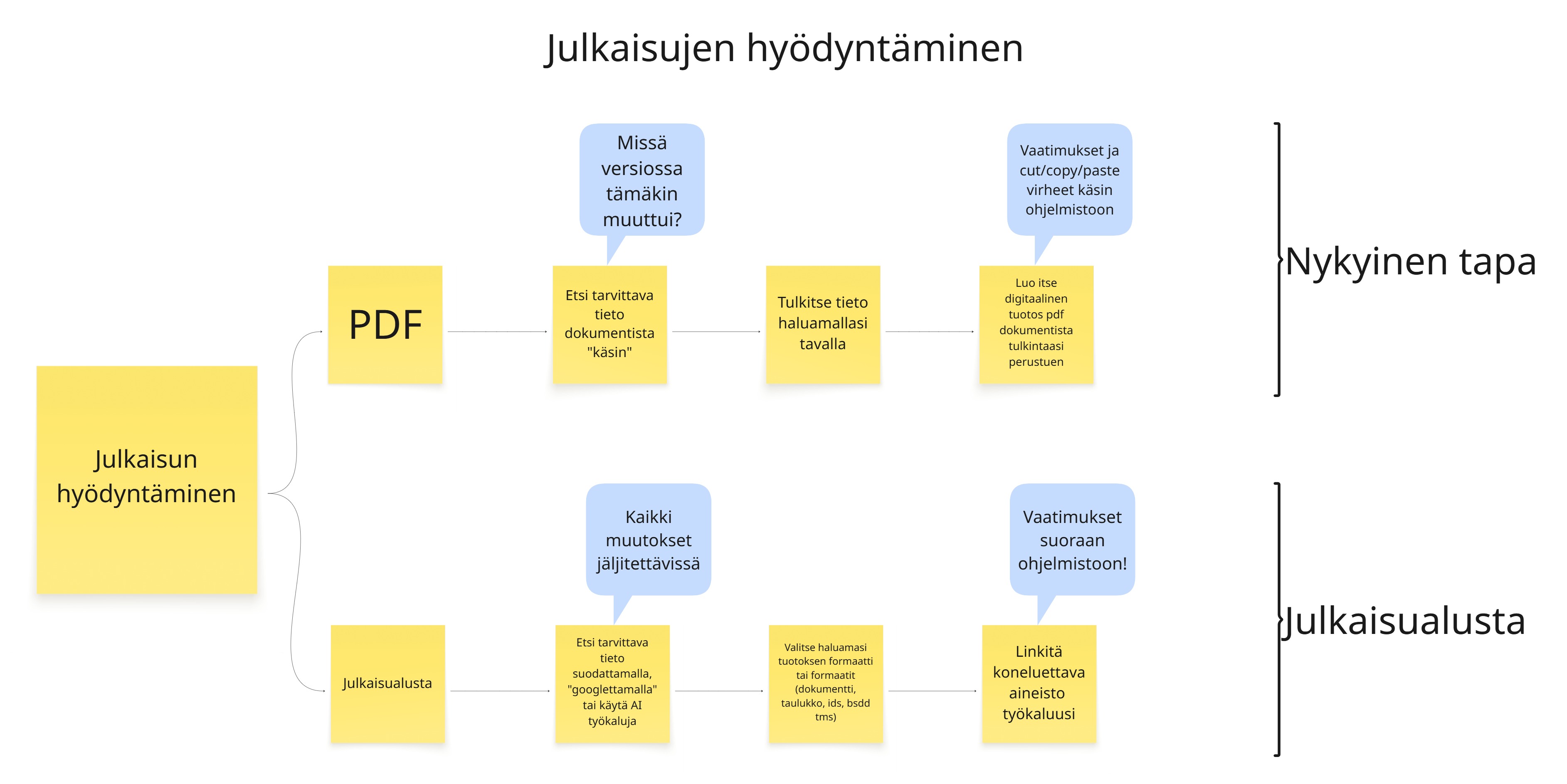
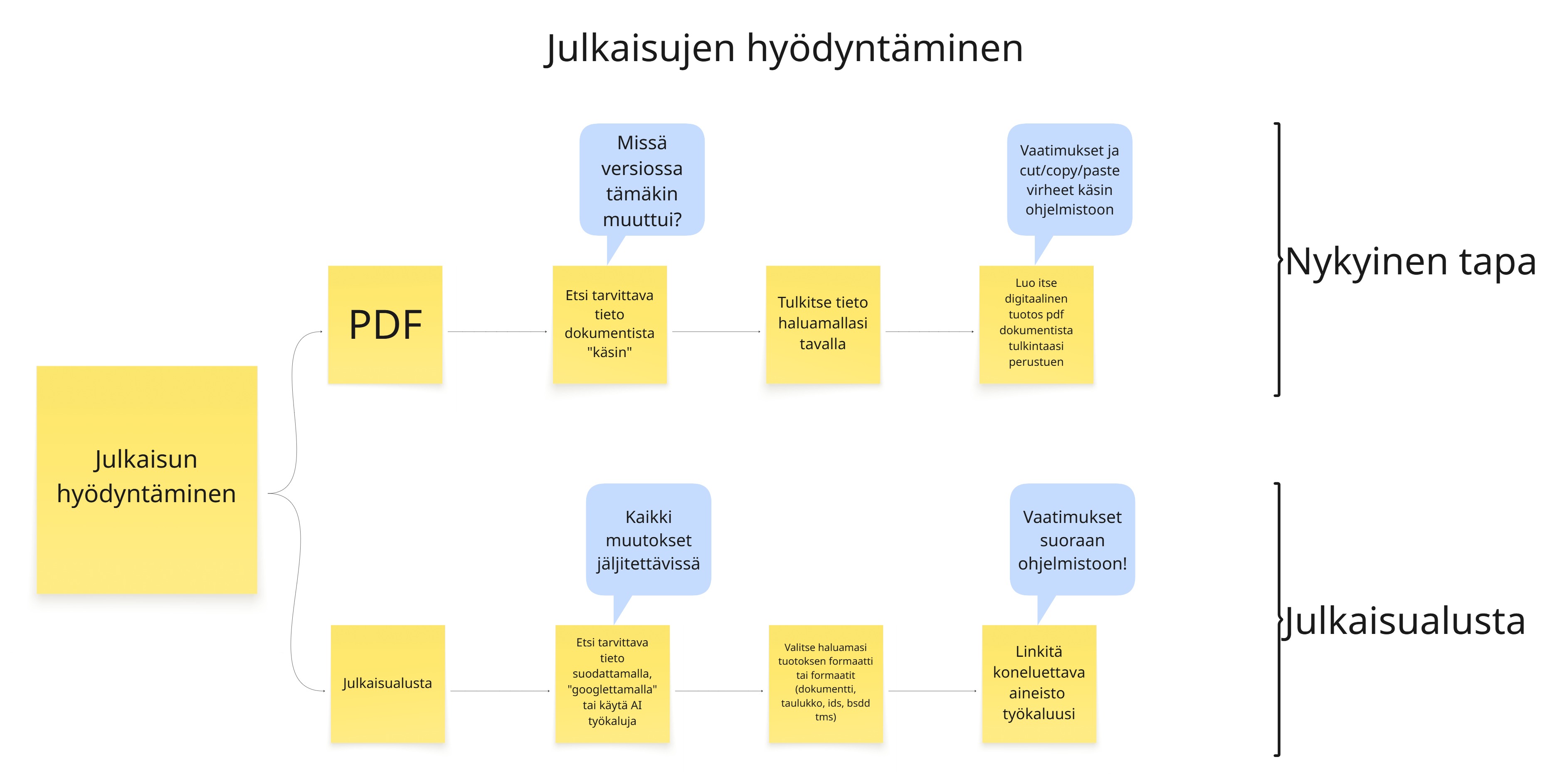
Julkaisujen hyödyntämistä julkaisualustan kautta on kuvattu seuraavassa kuvassa. Kuvassa verrokkina myös nykyinen tapa.
{kind=link}
¶ Miksi tämä on hyödyllistä kaikille?
Projektiryhmän kehittämä malli tarjoaa selkeän suunnan kohti semanttisesti yhteentoimivia määrittelyjä, joissa yhdistyvät laadukkaat, loogisesti rakennetut asiakirjat ja automaattisesti validoitava sisältö. Muutos auttaa vähentämään päällekkäistä työtä, mahdollistaa tehokkaamman tiedonhallinnan ja parantaa standardien hyödyntämistä niin toimijoiden sisällä kuin niiden välisessä yhteistyössä. Ratkaisu pohjautuu avoimiin teknologioihin ja standardeihin, mikä varmistaa joustavuuden ja helpottaa kotimaisen tarpeen mukaisen kehitystyön nopeaa etenemistä.
Kun tekniset määrittelyt tehdään koneymmärrettävinä, ne muuttuvat helposti hallittaviksi, ajantasaisiksi ja integroitaviksi erilaisiin käyttötapauksiin. Tämä vähentää tuottavan työn päällekkäisyyksiä ja mahdollistaa tietoihin perustuvan päätöksenteon jo automaattisesti. Lopputuloksena saavutetaan parempi laatu, pienemmät kustannukset ja entistä tehokkaampi tiedonhallinta – hyötyä, joka tarkoittaa selkeämpiä ja luotettavampia tietotuotteita ja palveluita.
¶ Tausta
KiRa-alan määrittelyt koostuvat lähes aina useista erillisistä dokumenteista, kaavioista, skeemoista, koodistoista, ym. aineistosta. Useita eri aineistotyyppejä tarvitaan, koska määrittely halutaan tarjota sekä koneluettavassa muodossa, että ihmisluettavassa muodossa. Lisähuomina todettakoon, että kaikkea tarvittavaa vaatimusta ei ole mahdollista nykypäivänä kuvata koneluettavassa muodossa, vaikka tälle merkittävä tarve olisikin.
Eri muotoisissa dokumenteissa ei tyypillisesti ole mahdollista viitata toistensa sisältöihin suoraan eikä hyödyntää yhdessä dokumentissa toisessa määriteltyä sisältöä. Sisältö joudutaan siis joko kopioimaan tai muuntamaan (joko käsin tai ohjelmallisesti) muodosta toiseen, mikä lisää tiedon toisteisuutta ja virheitä.
Monet aiemmin tuotetut määrittelyt on tarkoitettu ensisijaisesti ihmisten hyödynnettäviksi. Niiden käyttöönotto, hyödyntäminen, päivittäminen ja erityisesti useamman määrittelyn käyttö yhdessä vaatii aina paljon manuaalista työtä (muutoksia ohjelmistoihin, tiedon konvertointia eri rakenteiden välillä jne.) sekä erityistä asiantuntemusta.
Tällä hetkellä käytössä olevat määrittelydokumentit (kuten YTV, YIV, nimikkeistöt, tiedonsiirtospesifikaatiot tai käyttötapauskuvaukset) kuuluvat yllä kuvattuun joukkoon. Niiden joukossa on myös formaaleja koneluettavia osia (kuten skeemoja), jotka ovat teknisesti yhteentoimivia ja täyttävät niille asetetut syntaktiset ja rakenteelliset vaatimukset, mutta niiden merkityssisältö (eli semantiikka) jää edelleen ihmisten tulkittavaksi.
Kiinteistö- ja rakentamisalan (KiRa-alan) keskeisiä ratkaistavia haasteita:
- määrittelyjen sisäisten ja niiden välisten virheiden havaitseminen on haastavaa ja korjaaminen työlästä
- määrittelyt ovat monitulkintaisia, mikä johtaa eriäviin toteutuksiin niitä sovellettaessa
- määrittelyjen sisällöissä on merkittävää päällekkäisyyttä
- määrittelyjä päivitettäessä niiden välisten riippuvuuksien ja päivitysten vaikutusten arviointi ovat kohtuuttoman työläitä
- määrittelyjen implementointi ohjelmistoihin on pitkälti manuaalista ja kallista
- määrittelyjen laajentaminen koskemaan uusia käyttötapaustarpeita on vaikeaa
- “valuviat” hyväksytään osaksi usein määrittelyjä ja niitä koitetaan kiertää pienillä täydentävillä päivityksillä tai soveltamisohjeilla
¶ Julkaisumalli
Tässä projektissa määriteltävän julkaisumallin ja sen varaan tuotettavan julkaisualustan keskeisenä tavoitteena on ratkaista yllä kuvatut ongelmat. Siinä missä projektissa tuotettava julkaisualusta varmistaa, että määrittelyt voidaan tuottaa ja hallita teknisesti yhdenmukaisen laatuisina, julkaisumalli varmistaa, että yhdenmukainen laadunvarmistus ulottuu myös sisällön puolelle ja toteutuu mahdollisimman pitkälle automaattisesti ja käyttäjästä riippumatta.
Julkaisumalli on siis prosessi, joka implementoidaan julkaisualustan avulla. Kyseessä siis ei ole manuaalinen prosessi, josta sisällöntuottaja joutuu ottamaan vastuun, vaan prosessi, jossa sisällöntuottaja voi edetä vain näkyvien, ennalta määriteltyjen ehtojen täyttyessä. Tämän ansiosta jokainen määrittely käy kuitenkin tuotantonsa aikana läpi pakolliset sisältöä koskevat laadunvarmistuksen askeleet (sisällön rajaus, tarkkuus, painotukset, sidosryhmien kommentit yms.).
¶ Perusteet
Julkaisumalli perustuu semanttisen Webin malliin sekä sen perustan muodostaviin teknologioihin. Kyseessä on lähes 30 vuoden aikana Webin perusteknologioiden (HTTP, URL) varaan kehitetty joukko standardeja (RDF, OWL, SHACL, URI, URN, SPARQL, jne.), joilla joka puolella käytössä olevaa HTTP-protokollaa sekä URL-osoitteita voidaan käyttää jo tuotetun tiedon rikastamiseen sekä sellaisen tiedon luomiseen, josta voidaan koneellisesti tehdä päättelyä (nk. inferenssi).
Näiden standardien lähtökohtana on se, että monilla eri aloilla (ja jopa alojen sisällä) samoja asioita kuvataan eri tietorakenteilla, eri käsitteillä ja eri rajauksin. Vaikka harmonisointi ja tietojen yhtenäistäminen on aina tavoiteltava ja toivottava päämäärä, sen toteuttaminen ei monissa tapauksissa ole mahdollista etenkään kattavasti. On siis keskeistä, että tietoa voidaan vaihtaa toimijoiden kesken myös tilanteessa, jossa se ei rakenteeltaan ole yhdenmukaista.
Semanttisen Webin paradigman keskeisiä periaatteita:
- Standardit tarjoavat mahdollisuuden osoittaa, että toimijan A ja toimijan B tietueet kuvaavat (ainakin joiltain osin) samaa kohdetta, vaikka tietorakenteet eroaisivat toisistaan.
- Standardit mahdollistavat ominaisuuspohjaisen päättelyn (koska tietueella A on tietyt ominaisuudet, sen voidaan päätellä olevan tyyppiä X).
- Kaikki sellaiset tiedot, jotka on epäsuorasti johdettavissa (pääteltävissä) voidaan automaattisesti “tehdä näkyviksi” konepäättelyllä. Tämä vähentää tiedon toisteisuutta sekä ristiriitaisuutta.
- Jo tuotettua tietoa ohjataan hyödyntämään viittaamalla, ei kopioimalla.
- Tietoa ei tarvitse kuvata toisteisesti eikä “virtauttaa” (eli monistaa, kuten perinteisesti tehdään) järjestelmästä toiseen, sillä semanttisessa muodossa kuvatun tiedon keskeinen idea on, että tietoon viitataan ja tietoa haetaan aina sen nimen (identiteetin), ei sijaintijärjestelmän perusteella.
- Tieto voidaan validoida sekä syntaksin osalta (kuten XML-skeemoissa, ts. tieto noudattaa tiettyä rakennetta), että loogisen johdonmukaisuuden osalta (tieto ei sisällöltään kuvaa ristiriitaisia asioita).
Edellä mainittuja kyvykkyyksiä kutsutaan “semanttiseksi yhteentoimivuudeksi”. Euroopan unionin yhteentoimivuuskehyksen määritelmää lainaten: “It ensures that the precise meaning of exchanged information is understood and preserved throughout exchanges between parties".
Semanttisen Webin standardit saivat alkunsa CERNistä ja niitä ovat olleet kehittämässä mm. “WWW:n isä" Tim-Berners Lee sekä lukuisat työryhmät, joissa on ollut jäseniä niin keskeisistä yrityksistä kuin tutkimusorganisaatioista. Nykyään niitä käytetään laajalti julkishallinnossa erityisesti Euroopan unionissa, jossa niiden hyödyntämistä myös säädellään nk. yhteentoimivuusasetuksella sekä EIF-yhteentoimivuuskehyksellä (European Interoperability Framework) ja sen puitteissa tuotetuilla työkaluilla ja määrityksillä. Useilla jäsenmailla on omia yhteentoimivuuden mahdollistavia ja sitä edistäviä toteutuksia (esimerkiksi Suomen Yhteentoimivuusalusta). Yksityisellä puolella yhteentoimivuutta hyödynnetään erityisen laajasti lääketieteen, tutkimuksen ja tekoälyn saralla. Lisäksi monilla suurilla yksityisillä toimijoilla on omia sisäisiä suljettuja toteutuksiaan, joten käyttö on paljon laajempaa kuin miltä näyttää.
KiRa-alan osalta on keskeistä, että bSI:n (buildingSMART International) bSDD-alusta (buildingSMART Data Dictionary) noudattaa perusteiltaan täsmälleen samoja standardeja: tiedot on nimetty URI-tunnuksin (Unified Resource Identifier) ja ne on saatavissa linkitettynä datana. Nämä molemmat ovat keskeinen edellytys semanttiselle yhteentoimivuudelle.
Määrittelyn reunaehtojen, tavoitteiden ja perusteiden määrittämiseksi tarkasteltiin kokonaisuudessaan seuraavia standardeja kolmessa pääkategoriassa:
¶ Semanttisen Webin yhteentoimivuutta koskevat standardit (implementointi- ja metataso)
- RDF 1.1 Concepts and Abstract Syntax (W3C Recommendation. 25.2.2014.) sekä RDF 1.2 Concepts and Abstract Syntax (W3C Working Draft. 5.5.2025.)
- W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes (W3C Recommendation. 5.4.2012.)
- RDF Schema 1.1 (W3C Recommendation. 25.2014.) sekä RDF 1.2 Schema (W3C Working Draft. 24.2.2025.)
- OWL 2 Web Ontology Language Document Overview (Second Edition) (W3C Recommendation 11.12.2012.)
- Shapes Constraint Language (SHACL) (W3C Recommendation. 20.7.2017.) sekä SHACL 1.2 Core (W3C First Public Working Draft. 18.3.2025.)
- SPARQL 1.1 Query Language (W3C Recommendation. 21.3.2013.) sekä SPARQL 1.2 Query Language (W3C Working Draft. 4.4.2025.)
- Uniform Resource Identifier (URI): Generic Syntax (IETF. Tammikuu 2005.)
¶ Muut yhteentoimivuutta yleisesti koskevat standardit (metataso)
- ISO 704:2022. Terminology work — Principles and methods.
- ISO 1087:2019. Terminology work and terminology science — Vocabulary.
- ISO/IEC 5394:2024. Information technology — Criteria for concept systems.
- ISO/IEC 11179-1:2023. Information technology — Metadata registries (MDR). Erityisesti osat 1-7, 31-35.
- ISO/IEC TR 19583-1:2019. Information technology — Concepts and usage of metadata. Erityisesti osat 1, 22, 23.
- ISO/IEC 19763-1:2023. Information technology — Metamodel framework for interoperability (MFI). Erityisesti osat 1, 3, 5-10, 12, 13, 16.
- ISO/IEC 19773:2011. Information technology — Metadata Registries (MDR) modules.
- ISO/IEC TR 20943-1:2003. Information technology — Procedures for achieving metadata registry content consistency. Erityisesti osat 1, 3, 5, 6.
- ISO/IEC 20944-1:2013. Information technology — Metadata Registries Interoperability and Bindings (MDR-IB). Erityisesti osat 1-5.
- ISO 21597-1:2020. Information container for linked document delivery — Exchange specification. Erityisesti osat 1-2.
- ISO/IEC 24707:2018. Information technology — Common Logic (CL) — A framework for a family of logic-based languages.
- ISO/IEC 21838-1:2021. Information technology — Top-level ontologies (TLO). Erityisesti osat 1-4.
- ISO 22274:2013. Systems to manage terminology, knowledge and content — Concept-related aspects for developing and internationalizing classification systems.
- IEC 62559. Use case methodology. Erityisesti osat 1-4.
¶ Rakennusalan yhteentoimivuutta koskevat standardit (substanssitaso)
- ISO 12006-2:2015. Building construction — Organization of information about construction works.
- ISO 19650-1:2018. Organization and digitization of information about buildings and civil engineering works, including building information modelling (BIM) — Information management using building information modelling.
- ISO 29481-1:2016. Building information models — Information delivery manual.
- ISO 23386:2020. Building information modelling and other digital processes used in construction — Methodology to describe, author and maintain properties in interconnected data dictionaries.
¶ Mallin toiminta
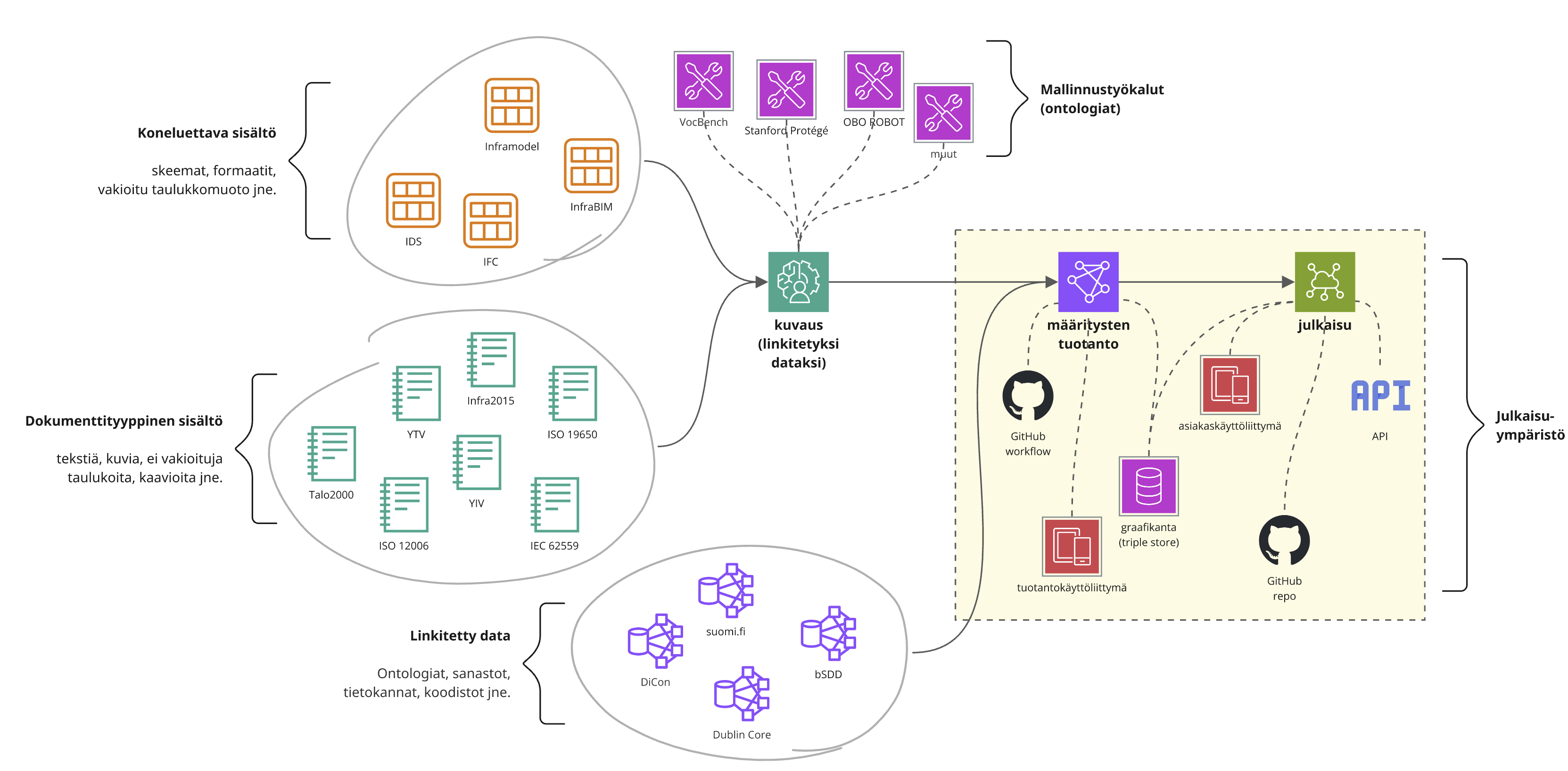
Mallin toiminta on kuvattu kuvassa 4. Prosessissa on kaksi tasoa:
- Metatason määritysten tuottaminen linkitetyksi dataksi
- Varsinaisten määritysten (julkaisujen) tuottaminen metatason määritysten varassa
Metatason määritykset tuotetaan ja validoidaan vakiintuneilla työkaluilla, joista merkittävä osa on avointa koodia. Metatason määritykset asettavat ne rakennetta ja sisältöä koskevat ehdot, joilla voidaan automaattisesti varmistaa, että tuotetut julkaisut ovat yhdenmukaisia (suhteessa metatason määrityksiin) ja täyttävät sisällöllisesti ja rakenteen puolesta halutut ehdot. Esimerkiksi IEC 62559 käyttötapauksia koskeva standardi voi toimia metatason määrityksenä, joka pakottaa kuvaamaan käyttötapauksia tietyn sabluunan (tiedon tuottaja, vastaanottaja, konteksti, tietosisältö jne.) puitteissa. Tämä on keskeisin julkaisumallin ero nykyiseen toimintatapaan verrattuna.
Metatason määrityksiä on KiRa-alalla tällä hetkellä vielä vain vähän semanttiseen muotoon julkaistuna, joten niiden tuottaminen (konversio) on yksi jatkuva kehitys- ja ylläpitotehtävä.
Varsinaiset määritykset luodaan bSF:n käyttötapauslomakkeiden sekä bSI:n UCM-alustan tapaan pääosin lomakepohjaisesti. Lomakkeiden sisältö, sallitut valinnat yms. ovat metatason määritysten mukaisia ja täytettävät kentät sekä sallitut arvot valikoituvat määrityksen tekijän valintojen perusteella.
Tuotettu määritys on aina automaattisesti validi suhteessa käytettyihin metatason määrityksiin, sillä määrittelyä ei pysty julkaisemaan alustalla elleivät kaikki vaaditut ehdot täyty. Tämän lisäksi toki aina tarvitaan myös sellaista sisältöä koskevaa validointia, jota ei ole järkevää formalisoida loogisiksi ehdoiksi – sidosryhmäkommentit ja tilaajan läpikäynti esimerkiksi ohjausryhmässä ovat edelleen tärkeitä.
Kun määritys julkaistaan, siitä generoidaan metamallista riippuen yksi tai useampi tietotuote:
- Uudelleenkäytettävä määrittely linkitetyn datan muodossa (ensisijainen)
- Ihmisluettava dokumentaatio (Markdown, PDF, ym.)
- Mahdolliset skeemat (esim. IDS)
- Mahdolliset prosessikaaviot (BPMN)
Näistä linkitetyn datan muodossa tuotettu julkaisu on keskeisin, sillä se on automaattisesti sellaisenaan uudelleenkäytettävissä tuleville määrityksille. Muut tietotuotteet ovat lopputuotteita ja johdannaisia, sillä niihin muunnettaessa menetetään aina vähintäänkin osa koneluettavasta semantiikasta.
Keskeisiä tavoitteita ovat tiivistetysti:
Määrittelyjen semanttisen yhteentoimivuuden parantaminen: Tavoitteena on rakentaa malli, jossa määrittelyjen merkityssisältö siirtyy eksplisiittiseksi niin, että tietokoneet pystyvät automaattisesti tarkistamaan ja yhdistämään tietoa
Yksinkertaistettu sisältöjen tuotanto ja päivitys: Uudessa mallissa pyritään vähentämään manuaalista työtä käyttämällä automatisoituja työkaluja, jotka muun muassa generoivat skeemat ja vastaavat muutosten validoinnista
Kumulatiiviset hyödyt niin määrittelyjä tekeviltä kuin niitä hyödyntäviltä tahoilta: Yhdenmukaisesti tuotettu määrittelyesineistö edistää tiedon yhteiskäyttöä ja toimintojen tehostamista, mikä vähentää päällekkäistä työtä ja mahdollistaa järjestelmien saumattoman integraation
¶ Julkaisualustan toteutus
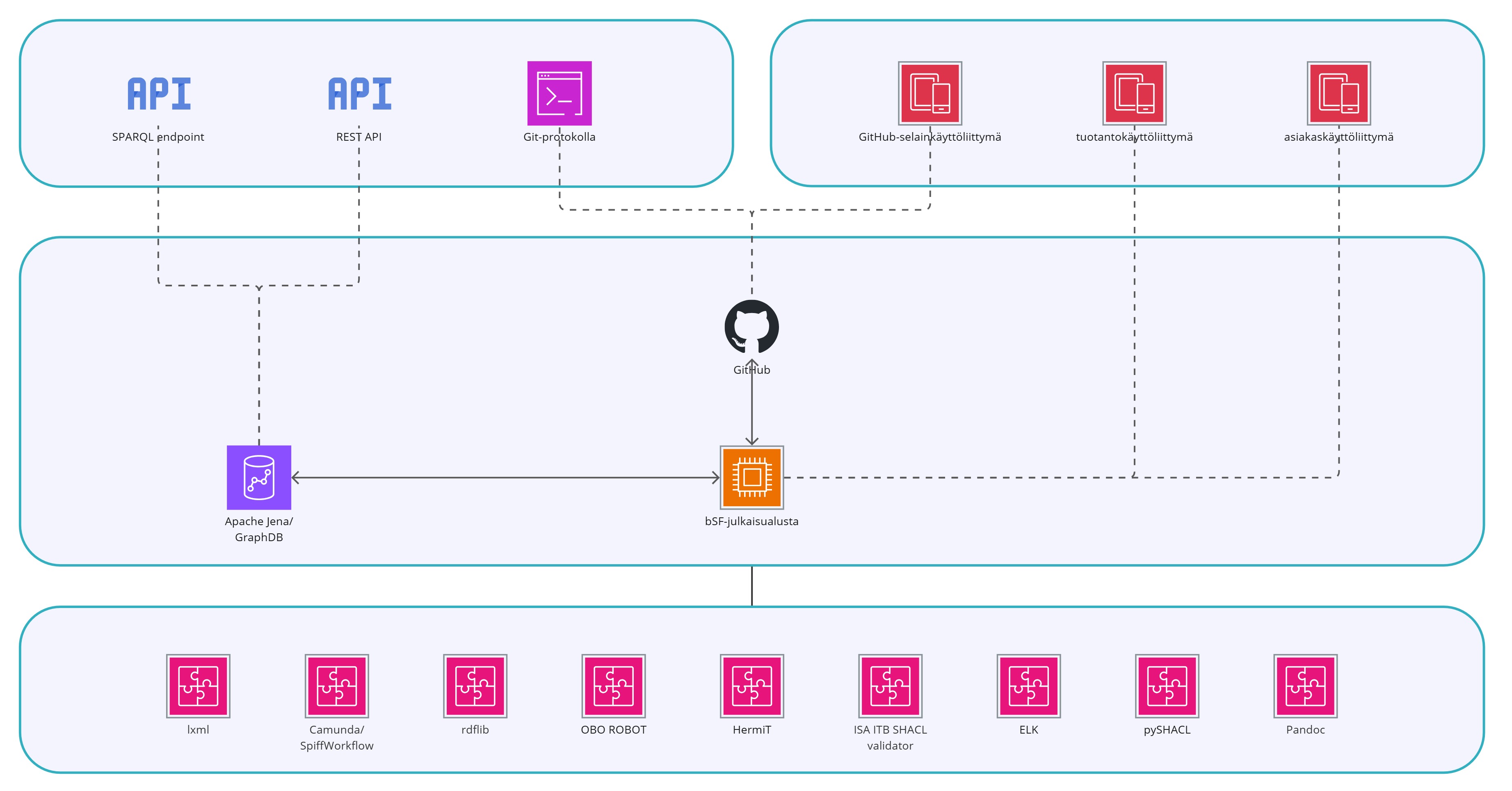
Julkaisualusta toteuttaa julkaisumallia kolmella keskeisellä osalla:
- Backend: julkaisujen ja metatason määritysten ydintietovaranto, validointi ja versionhallinta tapahtuu täällä
- Rajapinta: julkaisujen johtaminen tietotuotteiksi ja määritysten koneellinen hyödyntäminen
- Frontend: julkaisujen tuottaminen sekä haku ja tarkastelu graafisella käyttöliittymällä
Julkaisualusta toteutetaan mahdollisimman pitkälle julkaisujen sisällöstä riippumattomana, toisin sanoen ohjelmistoon pyritään kovakoodaamaan mahdollisimman vähän rajoitteita, jotka pakottavat tuottamaan sisältöä tietyllä tavalla tai estävät tietyn tyyppisen sisällön tuottamisen kokonaan. Tätä kutsutaan nk. data-driven eli tieto-ohjatuksi arkkitehtuuriksi. Julkaisualustan sabluunan eli validien määrittelyjen reunaehdot toteutetaan metatason skeemoilla, ja itse myös käyttöliittymän komponentit luodaan näiden skeemojen pohjalta. Tämän ansiosta itse ohjelmiston koodia tarvitsee muokata minimaalisesti ja erilaisten julkaisujen tuottaminen tapahtuu optimaalisessa tilanteessa kokonaan vain metatason skeemojen luonnin kautta.
Backend toteutetaan nk. triple storen eli graafitietokannan varaan, joka tukee natiivisti semanttista konepäättelyä ja tarjoaa keskeiset REST- ja SPARQL-rajapinnat. Tähän vahvimpia kandidaatteja ovat Apachen avoimen koodin Jena sekä suljetun koodin GraphDB. Rajapintaan on saatavilla lisäksi lukuisia muita hyvin vakaita kirjastoja kuten RDF4j.
Julkaisujen tuotanto ohjataan Github-workflowille, joka ajaa halutut muunnokset esimerkiksi PDF-dokumenteiksi ja prosessimalleiksi. Prosessimallien tuotantoon hyödynnetään Camunda- tai SpiffWorkflow-kirjastoja, jotka tukevat keskeistä prosessimallinnuksen standardia (BPMN).
Frontend toteutetaan responsiivisesti moderneilla Web-teknologioilla (esim. Svelte).
¶ Tuotokset ja jatkotoimenpiteet
Seuraavassa vaiheessa, nimeltään "Julkaisualustan kehittäminen osa B", projektin pääfokus on toteuttaa julkaisualustan tuotantoympäristö sisältäen taustajärjestelmät sekä tuotanto- ja asiakaskäyttöliittymän. Osa B projektissa varmistetaan, että kaikki prosessit ja tekniset ratkaisut ovat riittävän vakaita ja kehittyneitä tukemaan laajamittaista käyttöä.
Julkaisualustan kehittäminen Osa A -projektissa tehtiin laaja taustaselvitys, jossa kartoitettiin alan vaikuttavat standardit ja analysoitiin nykyisten bSF-julkaisujen tila. Tämän pohjalta kuvattiin julkaisumalli sekä -järjestelmä ja laadittiin tavoitetila, joka kuvaa innovatiivisen julkaisumallin sekä järjestelmän arkkitehtuurin ja mahdollistaa bSF-julkaisujen tuottamisen ja jakamisen ihmis- ja koneluettavasti. Julkaisumallin toiminnan ja määrittelyiden osalta laadittiin tuotantokäyttöliittymän toiminnasta PoC (Proof Of Concept, kuvassa 5), jonka avulla pyrittiin kuvaamaan julkaisumallin toimintaa käytännön esimerkillä.
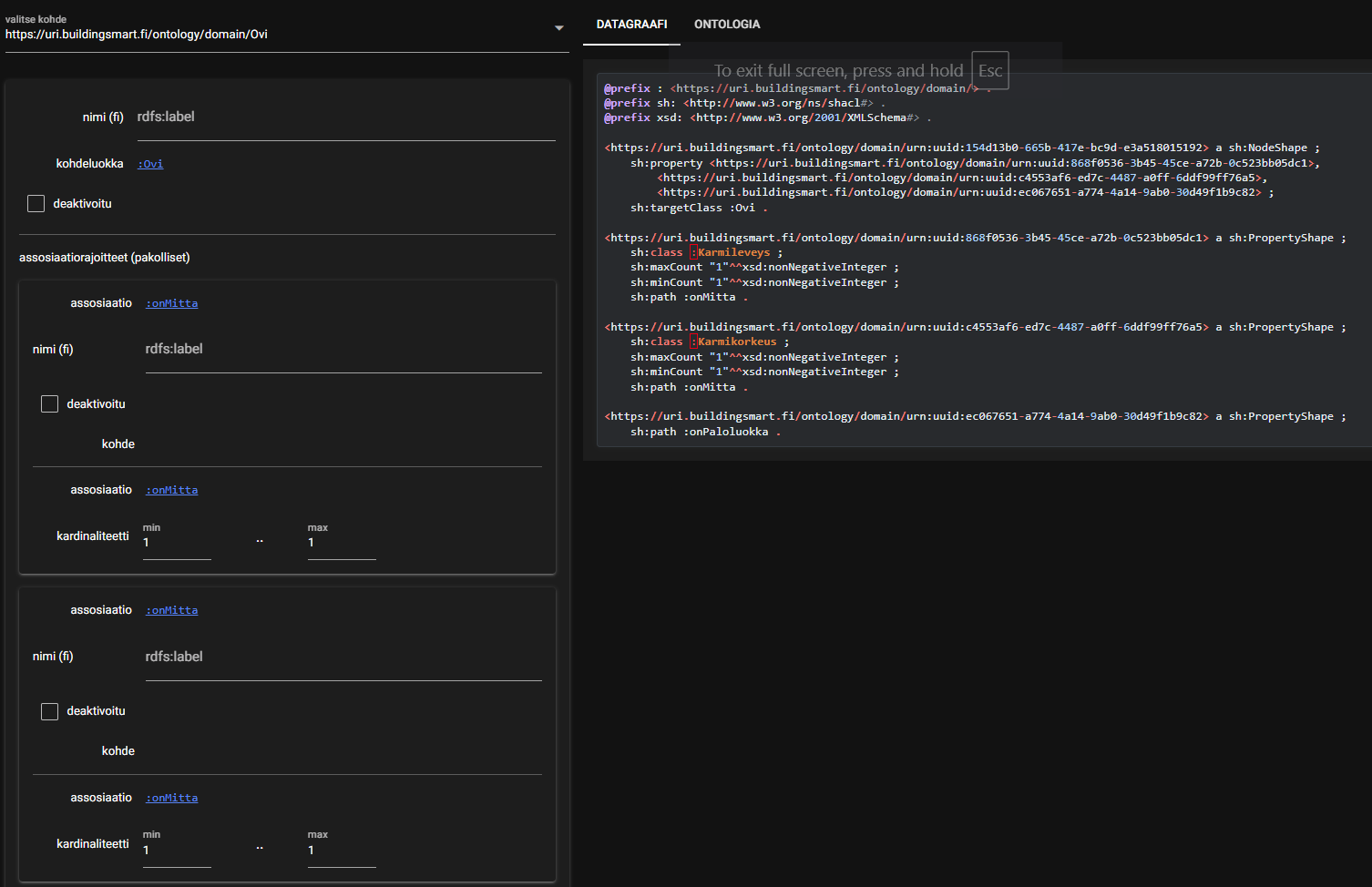
PoCissa havainnollistetaan julkaisumallin toimintaa käytännössä: siinä otettiin esimerkkiaineistoksi Ovien hankintapaketti asuntotuotannossa ja tuotettiin metaskeema, jonka puitteissa kyseisen hankintapaketin vaatimuksia voidaan määritellä. Kyseessä on nk. tietopohjainen arkkitehtuuri (engl. Data-Driven Architecture). Ideana on, että metatasoinen skeema määrittää, mitä esimerkiksi ovien hankinnan vaatimuksia tuottava taho voi skeemaan syöttää vaatimuksiksi. Tämä mukailee esimerkiksi IEC 62559-standardin mukaista vaatimusmäärittelyn rakenteen metatasoista sabluunaa. Kun ovien (tai jonkin muun kontekstin) hankinnan vaatimuksia määrittävä taho luo skeemaa, hänen ei tarvitse muistaa eikä itse varmistaa sitä, että kaikki olennaiset hankintaa koskevat vaatimukset tulevat mukaan skeemaan: julkaisualusta validoi tuotettavan hankintapaketin metaskeeman mukaisena jo sitä tuotettaessa. Käyttöliittymään syötettävä tieto syntyy suoraan määrittelynä tietokantaan (alla olevassa kuvassa datagraafi-otsikon alla oleva sisältö).
Määrittelemällä erilaisia metaskeemoja syntyy julkaisualustalle useita erilaisia skeeman ohjaamia käyttöliittymiä eri tietoalueiden ja eri tyyppisten spesifien vaatimusmäärittelyjen tuottamiseen. Jokainen käyttöliittymä samalla huolehtii siitä, että sen edellyttämät minimivaatimukset vaatimusmäärittelyn johdonmukaisuuden ja laadun osalta tulevat täytetyiksi. Malli ohjaa siis ohjelmistotuotantoa pois kiinteästi käsin rakennetuista käyttöliittymistä kohti datalähtöisiä käyttöliittymiä. Tämä tekee julkaisualustasta äärimmäisen joustavan.
PoC ei vastaa käyttäjäkokemuksen (UX) osalta vielä millään tavoin varsinaista B-osassa toteutettavaa tuotantokäyttöliittymää. PoCin tavoitteena on ollut ainoastaan demonstroida, että itse periaate käyttöliittymän dynaamisesta luomisesta metatason määrittelyjen muodostamilla ehdoilla on toteutuksena toimiva.
Alla kuvattuna Julkaisujärjestelmän arkkitehtuuri, jonka perusteella Julkaisujärjestelmän kehittäminen Osa B projektissa toteutettava julkaisujärjestelmän ja -mallin tuotantoympäristö tullaan toteuttamaan. Alustan käyttäjälle tämä tulee näkymään tuotanto- ja asiakaskäyttöliittymänä, joiden avulla julkaisuja tuotetaan ja ylläpidetään sekä jaetaan intuitiivisten käyttöliittymien avulla.
Kehitystyön määrittelyssä on selvitetty toimenpiteet, jotka ovat välttämättömiä julkaisujärjestelmän ensimmäisen tuotantoversion (MVP) synnylle. Lisäksi on laadittu alustavat suunnitelmat tulevien versioiden kehittyvistä toiminnoista, kuten BPMN generointi, mikä nostaa dokumenttien automaattisten kuvaamistapojen luomisen uudelle tasolle.
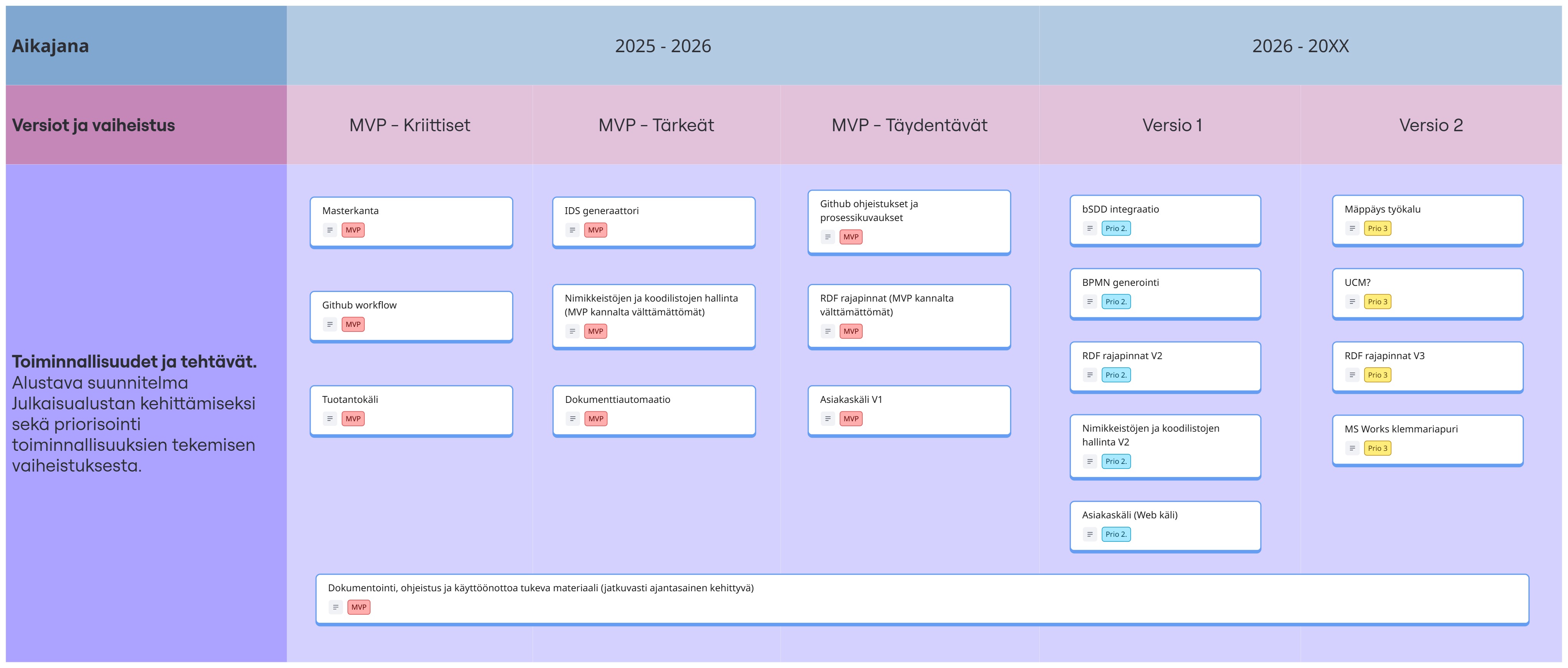
Seuraava Osa B -projekti toteutetaan agile-menetelmillä, mikä mahdollistaa joustavan ja dynaamisen lähestymistavan kehitykseen. Tämän osan päämääränä on varmistaa julkaisualustan käyttökelpoisuus tuotantoympäristössä, dokumentoida arkkitehtuuri, toteuttaa kehitys, ja vastata käyttäjien kehittyviin tarpeisiin. Kansainvälistä yhteistyötä laajennetaan, esimerkiksi tšekkiläisten asiantuntijoiden kanssa, mikä tukee projektin laajempaa kasvua ja potentiaalista kaupallista kehitystä. Julkaisualustan kehitys mahdollistaa merkittävää lisäarvoa rakennusalan vaatimusten hallintaan, samalla kun se avaa ovet uusille teknologioille ja innovaatioille tulevaisuudessa.
Käyttäjälähtöinen kehitys on keskiössä, ja käyttäjien tarpeet huomioidaan jatkuvasti aktiivisesta palautteesta ja käynnissä olevista ja tulevista RYTV projekteista Julkaisualustan kehittämisen yhteydessä.
Tämän artikkelin lisäksi projektissa laadittiin projektiehdotus Julkaisualustan kehittäminen osa B projektille sekä artikkelia täydentävä tekninen dokumentaatio.
Linkki: Julkaisualustan kehittäminen osa B projektiehdotus
Linkki: Tekninen dokumentaatio
Projektista pidettiin esitys BIM-Päivässä 6.5.2025. Esitys pdf muodossa löytyy seuraavasta linkistä: BIM päivä - bSF julkaisut nyt ja tulevaisuudessa
Projektiryhmä
Jari Kainuvaara, Sitowise (Projektipäällikkö)
Mikko Vesanen, Novatron (Asiantuntija)
Otso Helenius, Ubigu (Asiantuntija)
Juha Hyvärinen, JHy Consulting (Laadunvarmistus)
RYTV-julkaisualustan kehittäminen osa A projekti toteutettiin 8/2024 - 5/2025 aikana.